# Data manipulation, transformation and visualisation
library(tidyverse)
# Nice tables
library(kableExtra)
# Simple features (a standardised way to encode vector data ie. points, lines, polygons)
library(sf)
# Spatial objects conversion
library(sp)
# Thematic maps
library(tmap)
# Colour palettes
library(viridis)
# Fitting multilevel models
library(lme4)
# Tools for extracting information generated by lme4
library(merTools)
# Exportable regression tables
library(jtools)8 Multilevel Modelling - Part 2
This chapter explains varying slopes and draws on the following references:
The content of this chapter is based on:
Gelman and Hill (2006) provides an excellent and intuitive explanation of multilevel modelling and data analysis in general. Read Part 2A for a really good explanation of multilevel models.
Multilevel Modelling (n.d.) is an useful online resource on multilevel modelling and is free!
8.1 Dependencies
This chapter uses the following libraries which are listed in the Section 1.4.1 in Chapter 1:
8.2 Data
For this chapter, we will data for Liverpool from England’s 2011 Census. The original source is the Office of National Statistics and the dataset comprises a number of selected variables capturing demographic, health and socio-economic of the local resident population at four geographic levels: Output Area (OA), Lower Super Output Area (LSOA), Middle Super Output Area (MSOA) and Local Authority District (LAD). The variables include population counts and percentages. For a description of the variables, see the readme file in the mlm data folder.1
1 Read the file in R by executing read_tsv("data/mlm/readme.txt") . Ensure the library readr is installed before running read_tsv.
Let us read the data:
8.3 Conceptual Overview
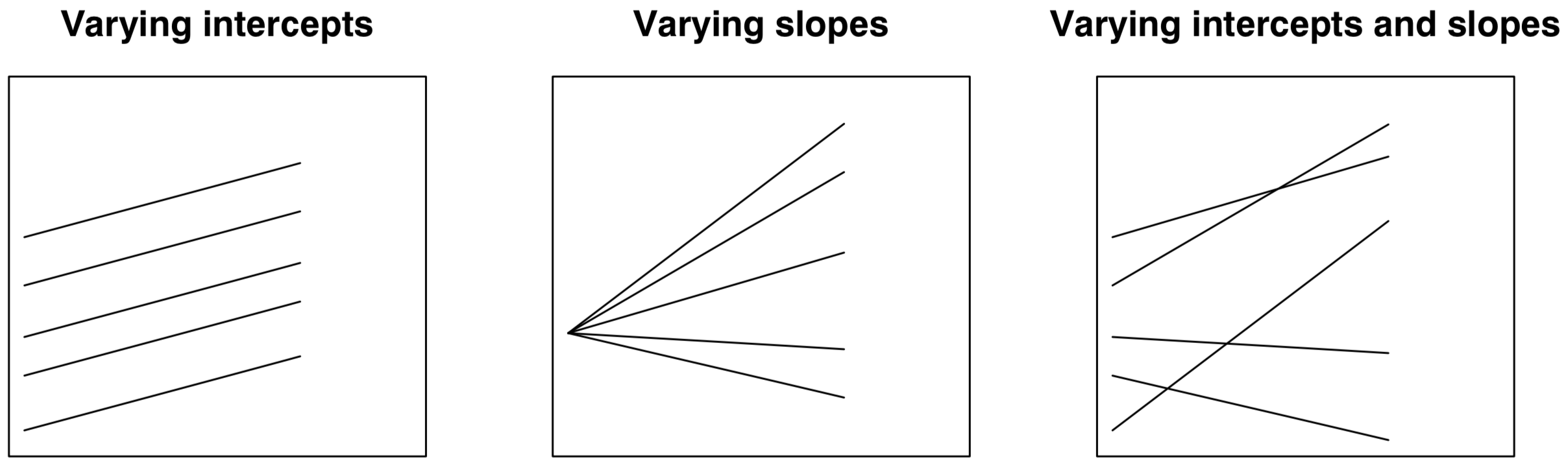
So far, we have estimated varying-intercept models; that is, when the intercept (\(\beta_{0}\)) is allowed to vary by group (eg. geographical area) - as shown in Fig. 1(a). The strength of the relationship between \(y\) (i.e. unemployment rate) and \(x\) (long-term illness) has been assumed to be the same across groups (i.e. MSOAs), as captured by the regression slope (\(\beta_{1}\)). Yet it can also vary by group as shown in Fig. 1(b), or we can observe group variability for both intercepts and slopes as represented in Fig. 1(c).
8.3.1 Exploratory Analysis: Varying Slopes
Let’s then explore if there is variation in the relationship between unemployment rate and the share of population in long-term illness. We do this by selecting the 8 MSOAs containing OAs with the highest unemployment rates in Liverpool.
Simple feature collection with 9 features and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 335032 ymin: 387777 xmax: 338576.1 ymax: 395022.4
Projected CRS: Transverse_Mercator
msoa_cd unemp geometry
1 E02001354 0.5000000 MULTIPOLYGON (((337491.2 39...
2 E02001369 0.4960630 MULTIPOLYGON (((335272.3 39...
3 E02001366 0.4461538 MULTIPOLYGON (((338198.1 39...
4 E02001365 0.4352941 MULTIPOLYGON (((336572.2 39...
5 E02001370 0.4024390 MULTIPOLYGON (((336328.3 39...
6 E02001390 0.3801653 MULTIPOLYGON (((335833.6 38...
7 E02001354 0.3750000 MULTIPOLYGON (((337403 3949...
8 E02001385 0.3707865 MULTIPOLYGON (((336251.6 38...
9 E02001368 0.3648649 MULTIPOLYGON (((335209.3 39...# Select MSOAs
s_t8 <- oa_shp %>% dplyr::filter(
as.character(msoa_cd) %in% c(
"E02001354",
"E02001369",
"E02001366",
"E02001365",
"E02001370",
"E02001390",
"E02001368",
"E02001385")
)And then we generate a set of scatter plots and draw regression lines for each MSOA.
ggplot(s_t8, aes(x = lt_ill, y = unemp)) +
geom_point() +
geom_smooth(method = "lm") +
facet_wrap(~ msoa_cd, nrow = 2) +
ylab("Unemployment rate") +
xlab("Long-term Illness (%)") +
theme_classic()`geom_smooth()` using formula = 'y ~ x'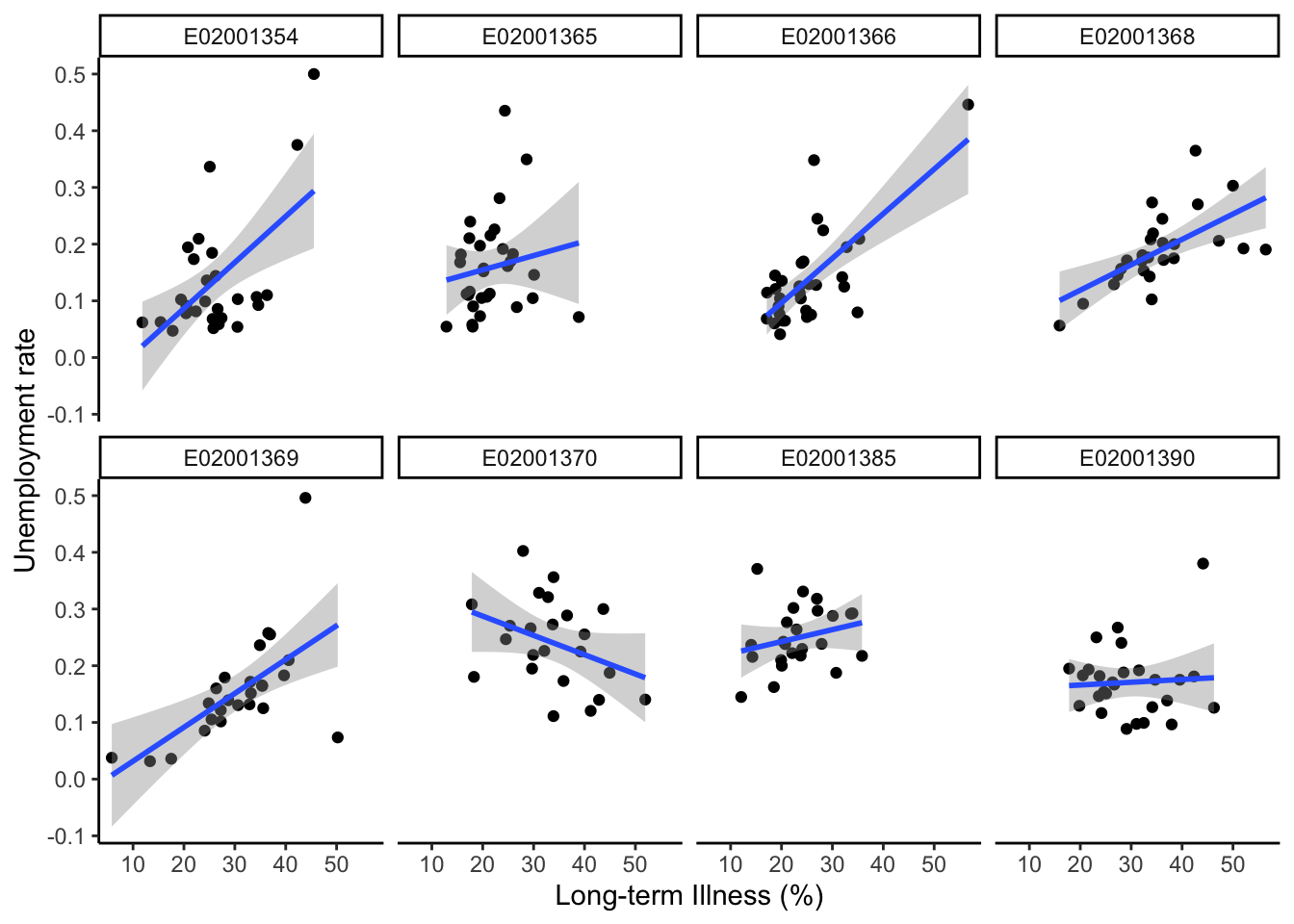
We can observe great variability in the relationship between unemployment rates and the percentage of population in long-term illness. A strong and positive relationship exists in MSOA E02001366 (Tuebrook and Stoneycroft), while it is negative in MSOA E02001370 (Everton) and neutral in MSOA E02001390 (Princes Park & Riverside). This visual inspection suggests that accounting for differences in the way unmployment rates relate to long-term illness is important. Contextual factors may differ across MSOAs in systematic ways.
8.4 Estimating Varying Intercept and Slopes Models
A way to capture for these group differences in the relationship between unemployment rates and long-term illness is to allow the relevant slope to vary by group (i.e. MSOA). We can do this estimating the following model:
OA-level:
\[y_{ij} = \beta_{0j} + \beta_{1j}x_{ij} + e_{ij}\]
MSOA-level:
\[\beta_{0j} = \beta_{0} + u_{0j}\] \[\beta_{1j} = \beta_{1} + u_{1j} \] Replacing the first equation into the second generates:
\[y_{ij} = (\beta_{0} + u_{0j}) + (\beta_{1} + u_{1j})x_{ij} + e_{ij}\] where, as in the previous Chapter, \(y\) the proportion of unemployed population in OA \(i\) within MSOA \(j\); \(\beta_{0}\) is the fixed intercept (averaging over all MSOAs); \(u_{0j}\) represents the MSOA-level residuals, or random effects, of the intercept; \(e_{ij}\) is the individual-level residuals; and, \(x_{ij}\) represents the percentage of long-term illness population. But now we have a varying slope represented by \(\beta_{1}\) and \(u_{1j}\): \(\beta_{1}\) is estimated average slope - fixed part of the model; and, \(u_{1j}\) is the estimated group-level errors of the slope.
To estimate such model, we add lt_ill in the bracket with a + sign between 1 and | i.e. (1 + lt_ill | msoa_cd).
Linear mixed model fit by REML ['lmerMod']
Formula: unemp ~ lt_ill + (1 + lt_ill | msoa_cd)
Data: oa_shp
REML criterion at convergence: -4762.8
Scaled residuals:
Min 1Q Median 3Q Max
-3.6639 -0.5744 -0.0873 0.4565 5.4876
Random effects:
Groups Name Variance Std.Dev. Corr
msoa_cd (Intercept) 0.003428 0.05855
lt_ill 0.029425 0.17154 -0.73
Residual 0.002474 0.04974
Number of obs: 1584, groups: msoa_cd, 61
Fixed effects:
Estimate Std. Error t value
(Intercept) 0.047650 0.008635 5.519
lt_ill 0.301259 0.028162 10.697
Correlation of Fixed Effects:
(Intr)
lt_ill -0.786In this model, the estimated standard deviation of the unexplained within-MSOA variation is 0.04974, and the estimated standard deviation of the MSOA intercepts is 0.05855. But, additionally, we also have estimates of standard deviation of the MSOA slopes (0.17154) and correlation between MSOA-level residuals for the intercept and slope (-0.73). While the former measures the extent of average deviation in the slopes across MSOAs, the latter indicates that the intercept and slope MSOA-level residuals are negatively associated; that is, MSOAs with large slopes have relatively smaller intercepts and vice versa. We will come back to this in Section Interpreting Correlations Between Group-level Intercepts and Slopes.
Similarly, the correlation of fixed effects indicates a negative relationship between the intercept and slope of the average regression model; that is, as the average model intercept tends to increase, the average strength of the relationship between unemployment rate and long-term illness decreases and vice versa.
We then explore the estimated average coefficients (fixed effects):
fixef(model6)(Intercept) lt_ill
0.04765009 0.30125875 yields an estimated regression line in an average LSOA: \(y = 0.04764998 + 0.30125916x\). The fixed intercept indicates that the average unemployment rate is 0.05 if the percentage of population with long-term illness is zero.The fixed slope indicates that the average relationship between unemployment rate and long-term illness is positive across MSOAs i.e. as the percentage of population with long-term illness increases by 1 percentage point, the unemployment rate increases by 0.3.
We look the estimated MSOA-level errors (random effects):
(Intercept) lt_ill
E02001347 -0.026561345 0.02718102
E02001348 0.001688245 -0.11533102
E02001349 -0.036084817 0.05547075
E02001350 0.032240842 -0.14298734
E02001351 0.086214137 -0.28130162Recall these estimates indicate the extent of deviation of the MSOA-specific intercept and slope from the estimated model average captured by the fixed model component.
We can also regain the estimated intercept and slope for each county by adding the estimated MSOA-level errors to the estimated average coefficients; or by executing:
#coef(model6)We are normally more interested in identifying the extent of deviation and its significance. To this end, we create a caterpillar plot:
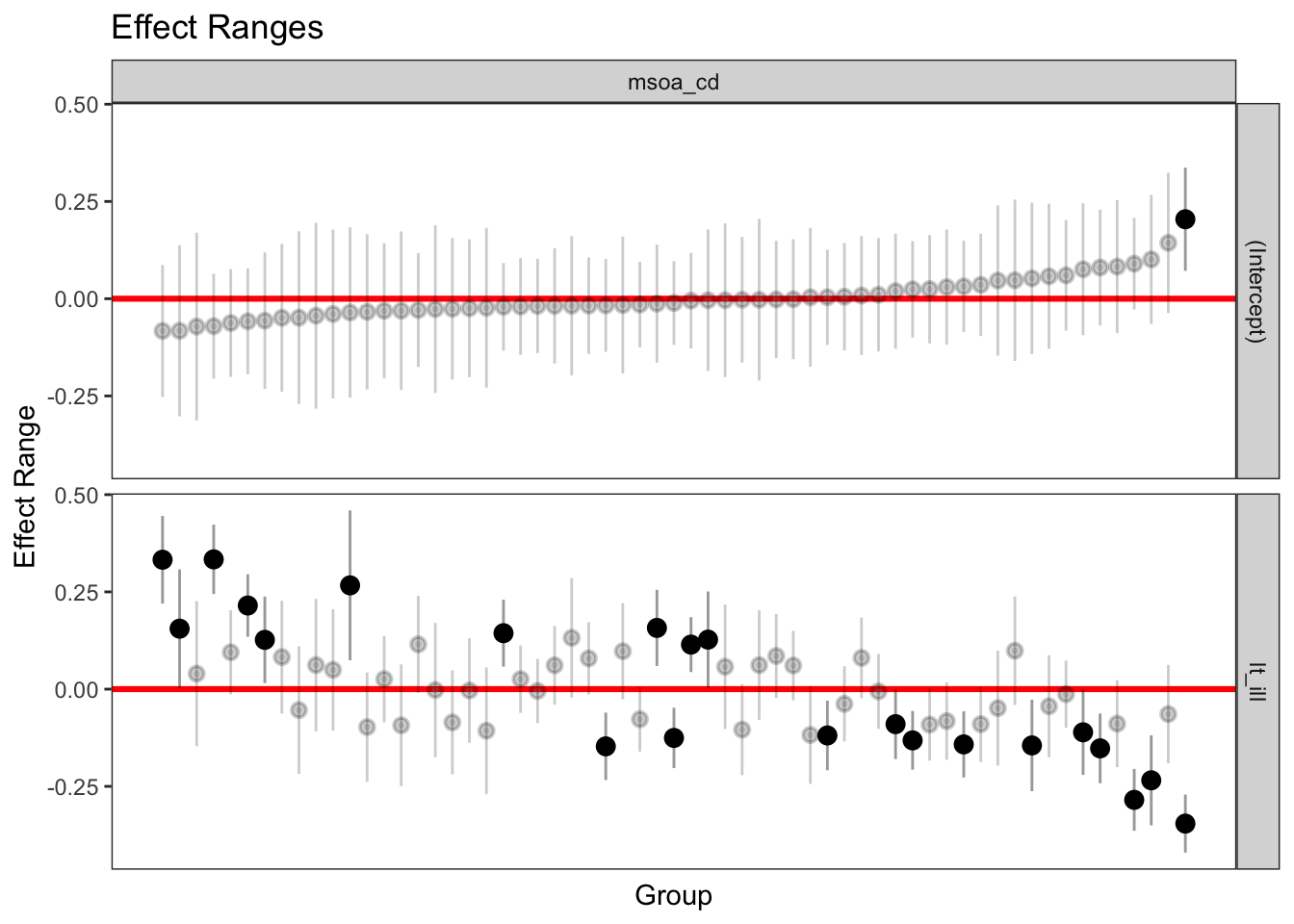
These plots reveal some interesting patterns. First, only one MSOA, containing wards such as Tuebrook and Stoneycroft, Anfield & Everton, seems to have a statistically significantly different intercept, or average unemployment rate. Confidence intervals overlap zero for all other 60 MSOAs. Despite this, note that when a slope is allowed to vary by group, it generally makes sense for the intercept to also vary. Second, significant variability exists in the association between unemployment rate and long-term illness across MSOAs. Ten MSOAs display a significant positive association, while 12 exhibit a significantly negative relationship. Third, these results reveal that geographical differences in the relationship between unemployment rate and long-term illness can explain the significant differences in average unemployment rates in the varying intercept only model.
Let’s try to get a better understanding of the varying relationship between unemployment rate and long-term illness by mapping the relevant MSOA-level errors.
# read data
msoa_shp <- st_read("data/mlm/MSOA.shp")Reading layer `MSOA' from data source
`/Users/franciscorowe/Library/CloudStorage/Dropbox/Francisco/uol/teaching/envs453/202526/san/data/mlm/MSOA.shp'
using driver `ESRI Shapefile'
Simple feature collection with 61 features and 17 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 333086.1 ymin: 381426.3 xmax: 345636 ymax: 397980.1
Projected CRS: Transverse_Mercator'data.frame': 61 obs. of 6 variables:
$ groupFctr: chr "msoa_cd" "msoa_cd" "msoa_cd" "msoa_cd" ...
$ groupID : chr "E02001347" "E02001348" "E02001349" "E02001350" ...
$ term : chr "lt_ill" "lt_ill" "lt_ill" "lt_ill" ...
$ mean : num 0.0283 -0.109 0.0482 -0.1435 -0.2815 ...
$ median : num 0.026 -0.1026 0.0444 -0.1419 -0.2818 ...
$ sd : num 0.0449 0.0752 0.0954 0.039 0.0367 ...# merge data
msoa_shp <- merge(x = msoa_shp, y = re_msoa_m6, by.x = "MSOA_CD", by.y = "groupID")# ensure geometry is valid
msoa_shp = sf::st_make_valid(msoa_shp)
# create a map
legend_title = expression("MSOA-level residuals")
map_msoa = tm_shape(msoa_shp) +
tm_fill(col = "median", title = legend_title, palette = magma(256, begin = 0, end = 1), style = "cont") +
tm_borders(col = "white", lwd = .01) +
tm_compass(type = "arrow", position = c("right", "top") , size = 4) +
tm_scale_bar(breaks = c(0,1,2), text.size = 0.5, position = c("center", "bottom")) ── tmap v3 code detected ───────────────────────────────────────────────────────[v3->v4] `tm_polygons()`: instead of `style = "cont"`, use fill.scale =
`tm_scale_continuous()`.
ℹ Migrate the argument(s) 'palette' (rename to 'values') to
'tm_scale_continuous(<HERE>)'
[v3->v4] `tm_polygons()`: use 'fill' for the fill color of polygons/symbols
(instead of 'col'), and 'col' for the outlines (instead of 'border.col').
[v3->v4] `tm_polygons()`: migrate the argument(s) related to the legend of the
visual variable `fill` namely 'title' to 'fill.legend = tm_legend(<HERE>)'
! `tm_scale_bar()` is deprecated. Please use `tm_scalebar()` instead.map_msoa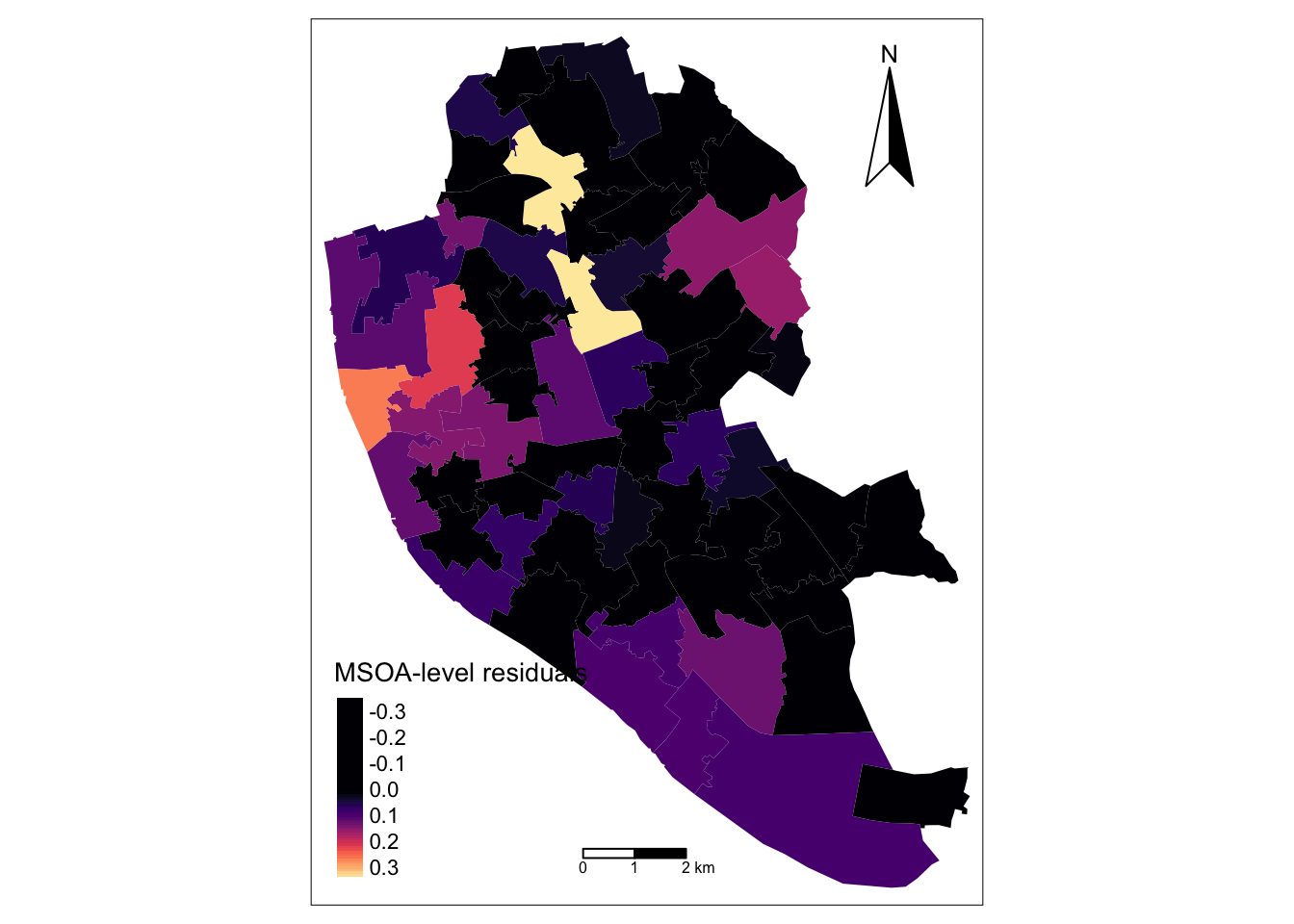
The map indicates that the relationship between unemployment rate and long-term illness is tends to stronger and positive in northern MSOAs; that is, the percentage of population with long-term illness explains a greater share of the variation in unemployment rates in these locations. As expected, a greater share of population in long-term illness is associated with higher local unemployment. In contrast, the relationship between unemployment rate and long-term illness tends to operate in the reverse direction in north-east and middle-southern MSOAs. In these MSOAs, OAs tend to have a higher unemployment rate relative the share of population in long-term illness. You can confirm this examining the data for specific MSOA executing:
oa_shp %>% dplyr::select(msoa_cd, ward_nm, unemp, lt_ill) %>%
filter(as.character(msoa_cd) == "E02001370")Simple feature collection with 23 features and 4 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 335885 ymin: 391134.2 xmax: 337596.3 ymax: 392467
Projected CRS: Transverse_Mercator
First 10 features:
msoa_cd ward_nm unemp lt_ill
1 E02001370 Everton 0.4024390 0.2792793
2 E02001370 Tuebrook and Stoneycroft 0.3561644 0.3391813
3 E02001370 Everton 0.3285714 0.3106383
4 E02001370 Everton 0.3209877 0.3283019
5 E02001370 Anfield 0.3082707 0.1785714
6 E02001370 Everton 0.3000000 0.4369501
7 E02001370 Everton 0.2886598 0.3657143
8 E02001370 Everton 0.2727273 0.3375000
9 E02001370 Everton 0.2705882 0.2534247
10 E02001370 Tuebrook and Stoneycroft 0.2661290 0.2941176
geometry
1 MULTIPOLYGON (((336328.3 39...
2 MULTIPOLYGON (((337481.5 39...
3 MULTIPOLYGON (((336018.5 39...
4 MULTIPOLYGON (((336475.7 39...
5 MULTIPOLYGON (((337110.6 39...
6 MULTIPOLYGON (((336516.3 39...
7 MULTIPOLYGON (((336668.6 39...
8 MULTIPOLYGON (((336173.8 39...
9 MULTIPOLYGON (((336870 3917...
10 MULTIPOLYGON (((337363.8 39...Now try adding a group-level predictor and an individual-level predictor to the model. Unsure, look at Section 7.4.5 and Section 7.4.6 in Chapter 7.
8.5 Interpreting Correlations Between Group-level Intercepts and Slopes
Correlations of random effects are confusing to interpret. Key for their appropriate interpretation is to recall they refer to group-level residuals i.e. deviation of intercepts and slopes from the average model intercept and slope. A strong negative correlation indicates that groups with high intercepts have relatively low slopes, and vice versa. A strong positive correlation indicates that groups with high intercepts have relatively high slopes, and vice versa. A correlation close to zero indicate little or no systematic between intercepts and slopes. Note that a high correlation between intercepts and slopes is not a problem, but it makes the interpretation of the estimated intercepts more challenging. For this reason, a suggestion is to center predictors (\(x's\)); that is, substract their average value (\(z = x - \bar{x}\)). For a more detailed discussion, see Multilevel Modelling (n.d.).
To illustrate this, let’s reestimate our model adding an individual-level predictor: the share of population with no educational qualification.
Linear mixed model fit by REML ['lmerMod']
Formula: unemp ~ z_lt_ill + z_no_qual + (1 + z_lt_ill | msoa_cd)
Data: oa_shp
REML criterion at convergence: -4940.7
Scaled residuals:
Min 1Q Median 3Q Max
-3.6830 -0.5949 -0.0868 0.4631 6.3556
Random effects:
Groups Name Variance Std.Dev. Corr
msoa_cd (Intercept) 8.200e-04 0.02864
z_lt_ill 2.161e-06 0.00147 -0.04
Residual 2.246e-03 0.04739
Number of obs: 1584, groups: msoa_cd, 61
Fixed effects:
Estimate Std. Error t value
(Intercept) 0.1163682 0.0039201 29.68
z_lt_ill -0.0003130 0.0003404 -0.92
z_no_qual 0.3245811 0.0221347 14.66
Correlation of Fixed Effects:
(Intr) z_lt_l
z_lt_ill -0.007
z_no_qual -0.015 -0.679How do you interpret the random effect correlation?
8.6 Model building
Now we know how to estimate multilevel regression models in R. The question that remains is: When does multilevel modeling make a difference? The short answer is: when there is little group-level variation. When there is very little group-level variation, the multilevel modelling reduces to classical linear regression estimates with no group indicators. Inversely, when group-level coefficients vary greatly (compared to their standard errors of estimation), multilevel modelling reduces to classical regression with group indicators Gelman and Hill (2006).
How do you go about building a model?
We generally start simple by fitting simple linear regressions and then work our way up to a full multilevel model - see Gelman and Hill (2006) p. 270.
How many groups are needed?
As an absolute minimum, more than two groups are required. With only one or two groups, a multilevel model reduces to a linear regression model.
How many observations per group?
Two observations per group is sufficient to fit a multilevel model.
8.6.1 Model Comparison
How we assess different candidate models? We can use the function anova() and assess various statistics: The Akaike Information Criterion (AIC), the Bayesian Information Criterion (BIC), Loglik and Deviance. Generally, we look for lower scores for all these indicators. We can also refer to the Chisq statistic below. It tests the hypothesis of whether additional predictors improve model fit. Particularly it tests the Null Hypothesis whether the coefficients of the additional predictors equal 0. It does so comparing the deviance statistic and determining if changes in the deviance are statistically significant. Note that a major limitation of the deviance test is that it is for nested models i.e. a model being compared must be nested in the other. Below we compare our two models. The results indicate that adding an individual-level predictor (i.e. the share of population with no qualification) provides a model with better.
anova(model6, model7)refitting model(s) with ML (instead of REML)Data: oa_shp
Models:
model6: unemp ~ lt_ill + (1 + lt_ill | msoa_cd)
model7: unemp ~ z_lt_ill + z_no_qual + (1 + z_lt_ill | msoa_cd)
npar AIC BIC logLik -2*log(L) Chisq Df Pr(>Chisq)
model6 6 -4764.7 -4732.5 2388.3 -4776.7
model7 7 -4956.5 -4918.9 2485.2 -4970.5 193.76 1 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 18.7 Questions
We will continue to use the COVID-19 dataset. Please see Chapter 11 for details on the data.
sdf <- st_read("data/assignment_2_covid/covid19_eng.gpkg")Reading layer `covid19_eng' from data source
`/Users/franciscorowe/Library/CloudStorage/Dropbox/Francisco/uol/teaching/envs453/202526/san/data/assignment_2_covid/covid19_eng.gpkg'
using driver `GPKG'
Simple feature collection with 149 features and 507 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 134112.4 ymin: 11429.67 xmax: 655653.8 ymax: 657536
Projected CRS: OSGB36 / British National GridUsing these data, you are required to address the following challenges:
Fit a varying-slope model. Let one slope to vary by region. Think carefully your choice.
Fit a varying-intercept and varying-slope model.
Compare the results for models fitted in 1 and 2. Which is better? Why?
Use the same explanatory variables used for the Chapter 7 challenge, so you can compare the model results from this chapter.
Analyse and discuss:
- the varying slope estimate(s) from your model(s) (to what extent does the relationship between your dependent and independent variables vary across groups / areas? are they statistically significantly different?).
- differences between your varying intercept and varying slope models.